




 Download
Download Buy
BuyPostgreSQL Maestro online Help
| Prev | Return to chapter overview | Next |
Indexes
Indexes are primarily used to enhance database performance (though inappropriate use may result in slower performance). The key field(s) for the index are specified as column names, or alternatively as expressions written in parentheses. Multiple fields can be specified if the index method supports multicolumn indexes.

Table indexes are created within the Index Properties dialog window. In order to open the dialog you should either
or
or
|
Table indexes are edited within the Index Properties dialog window. In order to open the dialog you should either
or
You can change the name of the index using the Rename Index dialog. To open the dialog you should either
or
|
To drop the table index:
or
and confirm dropping in the dialog window.
|
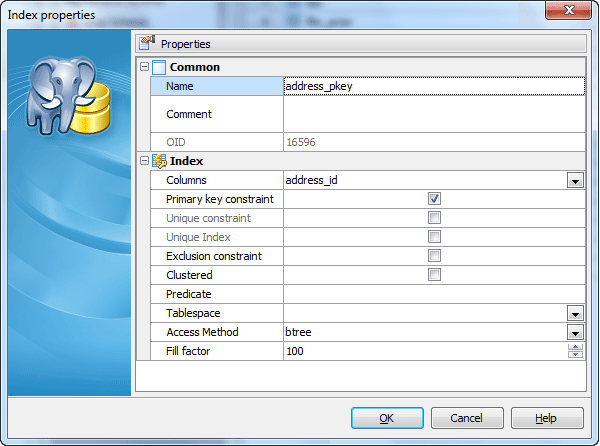
Use the Columns drop-down list to select a key field(s) for the index. Specify the index sort order and Nulls order (First means the index sorts nulls before non-nulls, Last - conversely).
Expression
An index field can be an expression computed from the values of one or more columns of the table row. This feature can be used to obtain fast access to data based on some transformation of the basic data. For example, an index computed on upper(col) would allow the clause WHERE upper(col) = 'JIM' to use an index. To set the index expression, use the Add expression button and enter the expression in the corresponding window.
Example
Suppose, there is a table Employee with the salary and premium fields and queries as follows are executed very often.
SELECT *
FROM "Employee"
WHERE "salary"+"premium">5000;
To create an index making such queries faster, set salary+premium as the index expression.
 Primary key constraint
Primary key constraint
With this option checked this field becomes a compound primary key. It is useful in case the table has more than one primary key.
Unique constraint
Check the option to permit no duplicate values. A unique column must also define the NOT NULL attribute. A table can have one or more unique keys.
Unique Index
If checked, creates a unique index for the table, i.e. the database system ensures that no two rows of the specified table have the same values in the indexed columns. In this way, if two rows both contain the NULL value for all columns of an index, the two index values are not considered to be identical. If at least one column does not contain the NULL value, two rows that have the same value in all non-NULL columns are considered to be identical.
Clustered
Fill the box to cluster the table based on the current index.
Note: When a table is clustered, it is physically reordered based on the index information. Clustering is a one-time operation: when the table is subsequently updated, the changes are not clustered. That is, no attempt is made to store new or updated rows according to their index order. If one wishes, one can periodically recluster by issuing the command again.
Predicate
Set the constraint expression to create a partial index. A partial index is an index that contains entries for only a portion of a table, usually a portion that is more useful for indexing than the rest of the table. For example, if you have a table that contains both billed and unbilled orders where the unbilled orders take up a small fraction of the total table and yet that is an often used section, you can improve performance by creating an index on just that portion.
Tablespaces define locations in the file system where the files representing table objects can be stored.
Access method
PostgreSQL provides several index types: B-tree, R-tree, Hash, and GiST. Each index type uses a different algorithm that best suits different types of queries. By default, the CREATE INDEX command will create a B-tree index which fits the most common situations.
| • | B-trees can handle equality and range queries on data that can be sorted into some ordering. |
| • | R-tree indexes are suited for queries on spatial data. |
| • | Hash indexes can only handle simple equality comparisons. The query planner will consider using a hash index whenever an indexed column is involved in a comparison using the '=' operator. |
| • | GiST indexes are not a single kind of index, but rather an infrastructure within which many different indexing strategies can be implemented. Accordingly, the particular operators with which a GiST index can be used vary depending on the indexing strategy (the operator class). |